
![]()


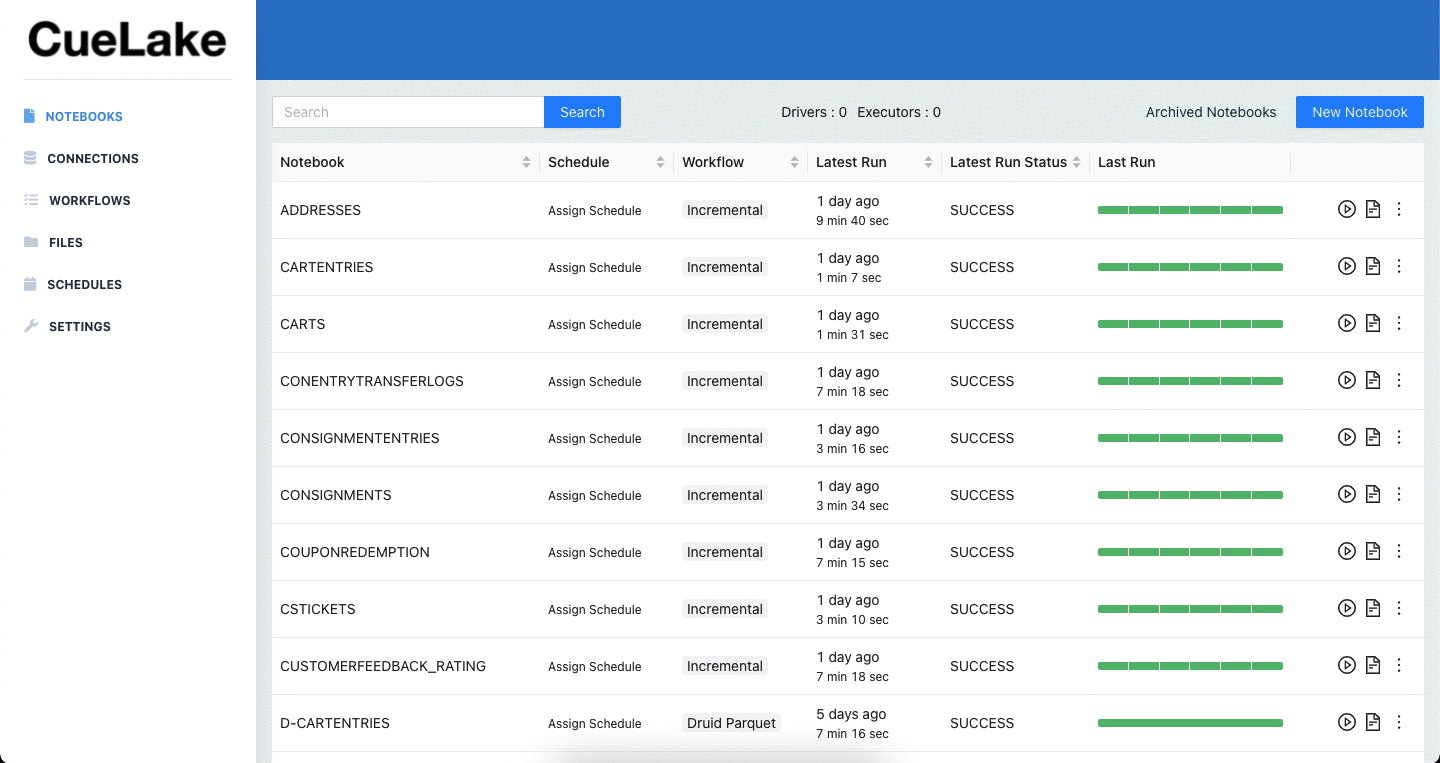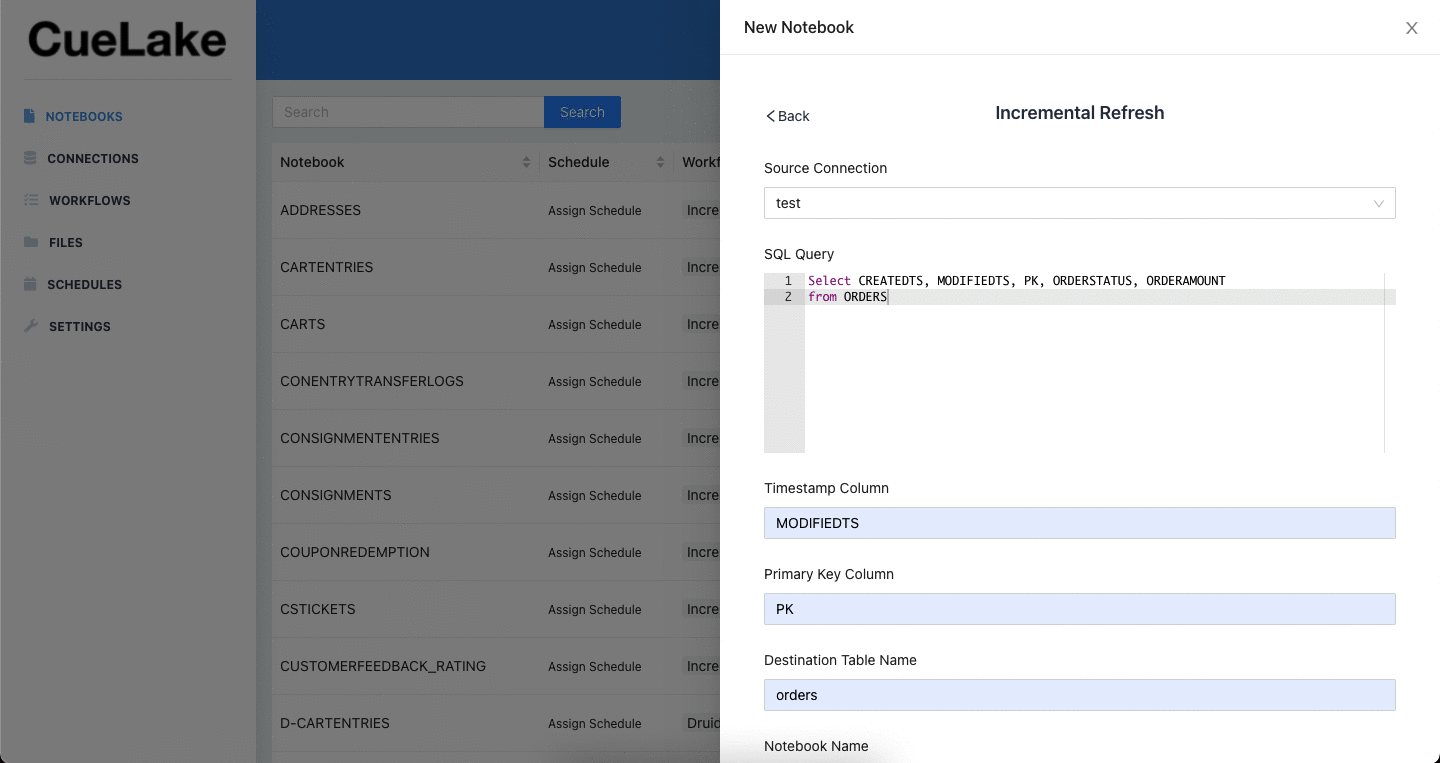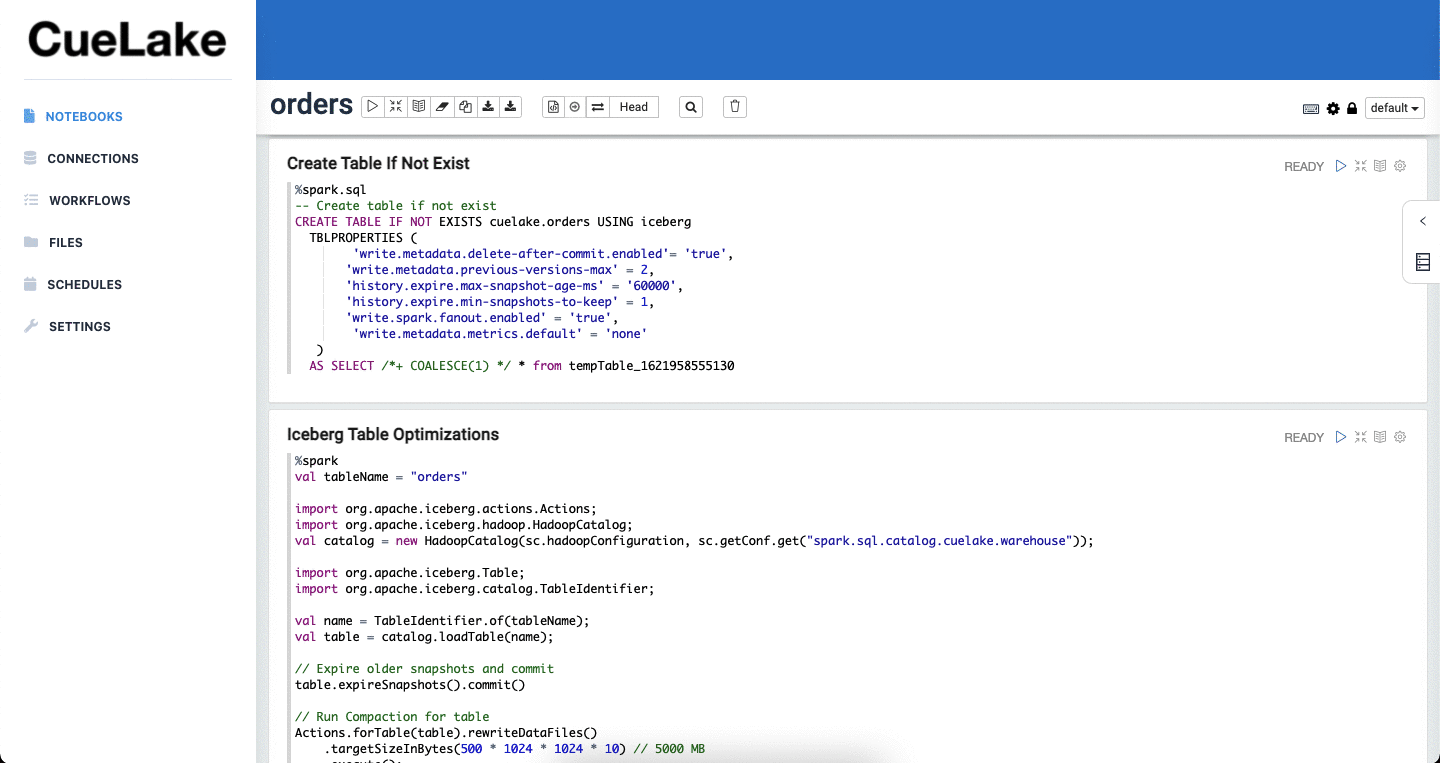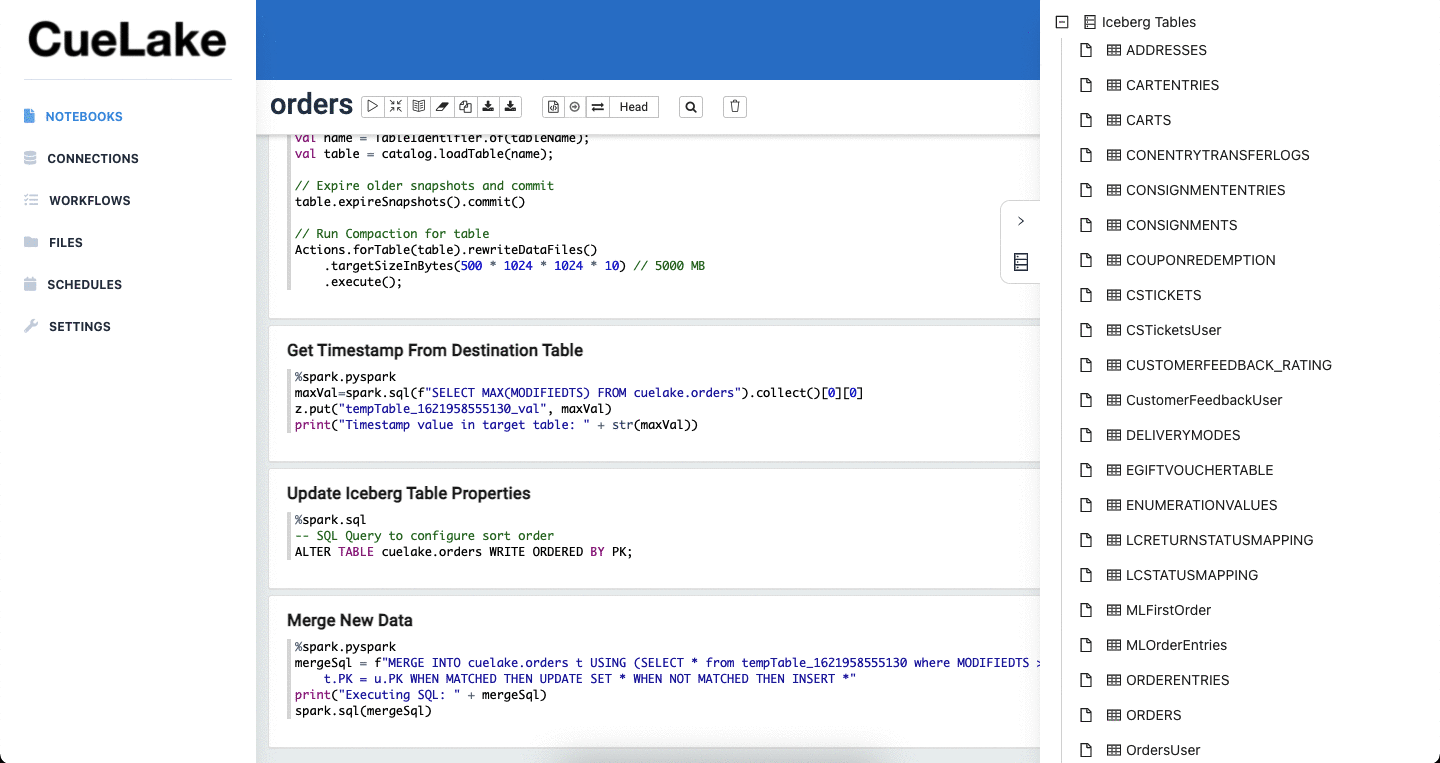
Overview
With CueLake, you can use SQL to build ELT (Extract, Load, Transform) pipelines on a data lakehouse.
You write Spark SQL statements in Zeppelin notebooks. You then schedule these notebooks using workflows (DAGs).
To extract and load incremental data, you write simple select statements. CueLake executes these statements against your databases and then merges incremental data into your data lakehouse (powered by Apache Iceberg).
To transform data, you write SQL statements to create views and tables in your data lakehouse.
CueLake uses Celery as the executor and celery-beat as the scheduler. Celery jobs trigger Zeppelin notebooks. Zeppelin auto-starts and stops the Spark cluster for every scheduled run of notebooks.
To know why we are building CueLake, read our viewpoint.
What is a Lakehouse?
A lakehouse is a new, open architecture that combines the best elements of data lakes and data warehouses (see Databricks articles here and here).
Features
- Upsert Incremental data. CueLake uses Iceberg’s
merge intoquery to automatically merge incremental data. - Create Views in data lakehouse. CueLake enables you to create views over Iceberg tables.
- Create DAGs. Group notebooks into workflows and create DAGs of these workflows.
- Elastically Scale Cloud Infrastructure. CueLake uses Zeppelin to auto create and delete Kubernetes resources required to run data pipelines.
- In-built Scheduler to schedule your pipelines.
- Automated maintenance of Iceberg tables. CueLake does automated maintenance of Iceberg tables - expires snapshots, removes old metadata and orphan files, compacts data files.
- Monitoring. Get Slack alerts when a pipeline fails. CueLake maintains detailed logs.
- Versioning in Github. Commit and maintain versions of your Zeppelin notebooks in Github.
- Data Security. Your data always stays within your cloud account.
Current Limitations
- Supports AWS S3 as a destination. Support for ADLS and GCS is in the roadmap.
Support
For general help using CueLake, read the documentation, or go to Github Discussions.
To report a bug or request a feature, open an issue.